周一早会,领导打开看板查营收,光标转了 30 秒还没出数。
千万行事实表全量扫描、几十个视觉对象同时触发查询、查询折叠覆盖率不到 30%——"慢"的本质是架构债。
本文拆解 2026 年最实战的组合方案:Direct Lake + 增量刷新 + 查询折叠,让秒开成为可复现的工程结论。
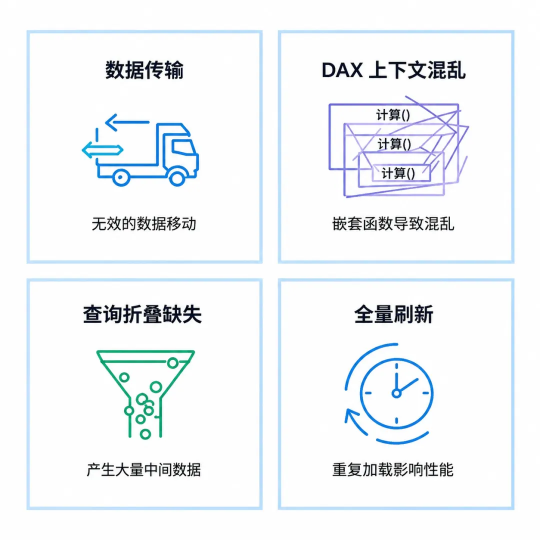
数据传输:导入模式全量数据先载入内存,事实表破千万行后刷新线性增长,亿级触发 OOM。
DAX 上下文混乱:多层 CALCULATE 嵌套迫使引擎在行/筛选上下文间反复跳转,延迟成倍放大。
查询折叠缺失:Power Query 筛选/合并未折叠到 SQL 端,数据被拉回本地暴力聚合,IO 量级上升。
全量刷新:每次跑全量,已不变的历史行重复加载,浪费 CPU 和带宽。
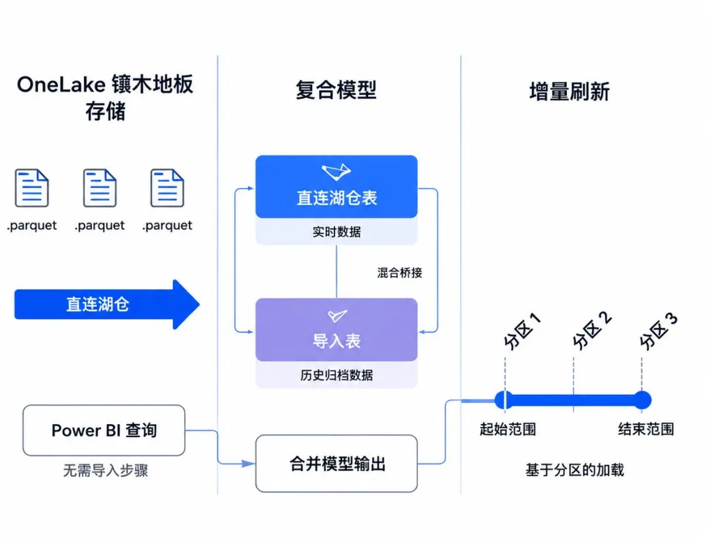
2026 年 Direct Lake 从实验功能走向生产级,打破"先导入再查询"的旧范式——数据不必离开 OneLake,直接读 Parquet 文件,近导入模式性能、零数据复制。
Direct Lake:热点数据从 OneLake 的 Parquet 直接定位读取,省去全量加载耗时。
复合模型:同模型混合 Direct Lake 与导入表,高频实时走 Direct Lake,历史归档走导入表。
增量刷新:配合 RangeStart/RangeEnd 参数分区级增量加载,数十亿行模型刷新从小时级压到分钟级。

Direct Lake 查询时通过列存储压缩的 Parquet 直接定位片段,刷新阶段计算和内存消耗断崖式下降。
增量刷新全量扫描变窗口扫描,历史归档导入表,近 30 天走 Direct Lake,引擎扫描量降 80%。
VAR 缓存 CALCULATE 结果减少上下文切换,时间智能筛选前推至度量值最外层。
业务价值直白:报表从"等一杯咖啡"到秒开,每次查看数据的摩擦力归零。每天被打开上百次的决策仪表板,这是直接的生产力提升。
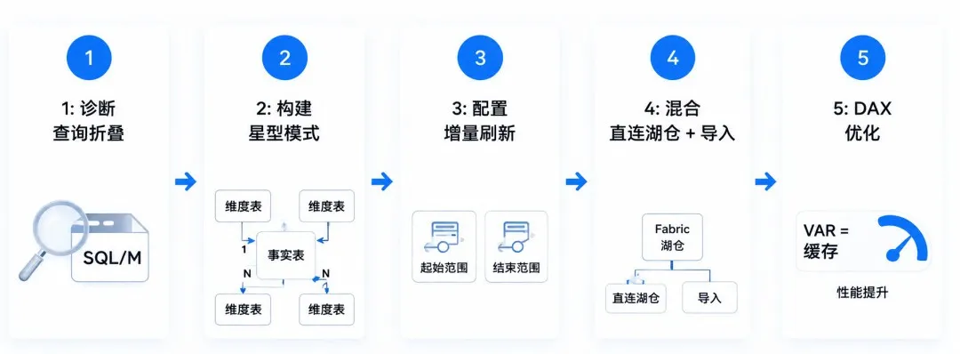
诊断查询折叠:Power Query 编辑器中右键步骤"查看本机查询"——见 SQL 即成功,仅 M 代码即失败。可折叠前置,不可折叠后置。
建立星型模型:维度表→事实表单向 1:N,杜绝双向关系与雪花模型,确保筛选传播路径清晰可预测。
配置增量刷新:定义 RangeStart/RangeEnd 参数,Service 中启用增量刷新,设置保留窗口(如保留 3 年仅刷近 3 天)。
混合 Direct Lake+ 导入:Fabric 中创建复合语义模型,高频表→Direct Lake,归档表→导入。2026 年 4 月新增 Direct Lake 计算列支持未物化计算列和 UserPrincipalName() 行级安全。
DAX 优化:VAR 缓存中间结果,减少高基数列,用 Fabric Notebook 分析模型内存与存储。
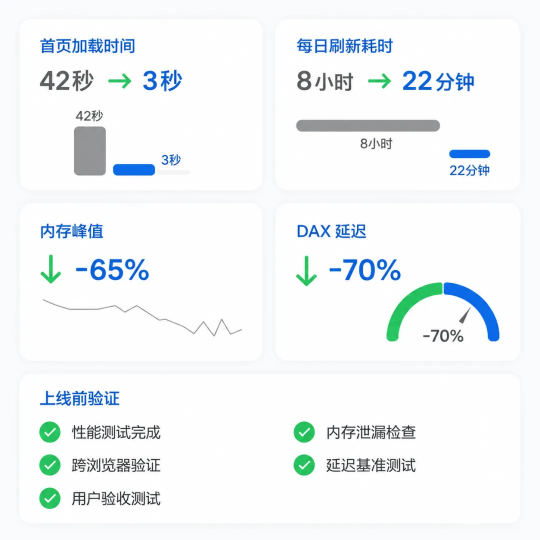
多个大型零售和制造客户验证,效果可量化:
首页加载:42 秒 → 3 秒
日刷新耗时:8 小时 → 22 分钟
内存峰值:降 65%
DAX 延迟:减 70%
上线前,五问自查清单:
1. Power Query 步骤是否已检查查询折叠?
2. 数据模型是否为星型,维度→事实单向 1:N?
3. 大表是否已启用增量刷新?
4. 实时数据是否走 Direct Lake 而非导入?
5. DAX 是否存在可消除的多层 CALCULATE 嵌套?
性能优化不是一次性项目,是架构思维的持续升级。Direct Lake + 增量刷新这条路径,本质在重新定义"大数据下 BI 该长什么样"。
建议从最简单的一步开始——打开 Power Query 编辑器,右键几个关键步骤,点击"查看本机查询"。你会惊觉:原来有这么多数据一直在做无谓的搬运。